


Table of Contents
Annotation Strategies for Subjective Tasks: Lessons from RLHF Projects

Let’s be real that AI is only as smart as the data we feed it. Whether you’re building a recommendation engine, training a vision model, or fine-tuning a large language model (LLM), your model’s behavior hinges on one thing: how well it’s aligned with human expectations.
Now, when that data involves subjective decisions — like whether an AI response feels helpful, respectful, or emotionally on point — the game changes completely.
In high-stakes AI projects, especially those using Reinforcement Learning from Human Feedback (RLHF), subjective annotation isn’t just a step in the pipeline — it is the pipeline. We’ve seen this up close in a project we worked on, where we had to judge LLM outputs against nuanced human values.
We’ll walk you through the strategies, tools, and hard-won lessons that helped us turn messy, opinion-driven tasks into reliable, scalable systems.
Why Subjective Tasks Break Traditional Annotation Playbooks
Let’s start with the obvious: subjective labels don’t come with a universal answer key. Sure, labeling a cat in an image or extracting named entities from text is straightforward. But rating how “kind” a chatbot sounds? Or which of the three responses is the most helpful? That’s murky.
In RLHF projects, where human feedback becomes the reward signal for model updates, these subjective calls carry even more weight. Misjudgments here can train your AI to act in ways that alienate users — or worse, reinforce harmful patterns.
How to Handle Subjective Annotation Without Losing Your Mind
We’ve tried and tested a range of strategies to make subjective annotation actually work. Here’s what we recommend:
1. Guidelines That Are Clear — but Not Rigid
You can’t remove ambiguity from subjective tasks, but you can equip annotators with better tools to navigate it.
- Offer examples across the good-to-bad spectrum
- Highlight edge cases and gray zones
- Keep updating guidelines as confusion points emerge
In our project, we built mini case studies — everything from “How helpful is this tone?” to “What counts as too vague?” — to guide our reviewers.
2. Bring in More Eyes: Multi-Rater Systems Work
Subjectivity thrives on perspective. So give your data just that.
- Use 3–5 annotators per sample
- Aggregate using majority vote or confidence weighting
- Track inter-rater agreement and flag divergence
Not only does this raise quality, but it also dilutes individual bias, making your dataset stronger.
3. Ditch Scores, Embrace Comparisons
A 1-to-5 star rating feels natural — until you’re knee-deep in conflicting interpretations. Instead, go comparative.
- “Which of these two responses is better?”
- “Rank these answers from best to worst.”
Pairwise ranking, a staple in RLHF, simplifies subjective evaluation and yields sharper training signals.
4. Calibrate Annotators Like You Would Calibrate a Sensor
Annotation is interpretive work, not a mechanical task. So calibration matters.
- Provide gold-standard examples
- Use pilot tasks to surface disagreement patterns
- Develop rater personas (e.g., expert vs. casual user) to ensure consistency across angles
This is especially critical when “right” can look like a few different things, depending on who’s judging.
5. Combat Fatigue, Bias, and Burnout
Subjective labeling is mentally heavy. People tire, drift, or get lazy.
- Rotate tasks and build in breaks
- Monitor per-rater quality metrics
- Run spot checks and offer live feedback
Why it matters: Tired annotators tend to play it safe, and “safe” often means boring, biased, or inconsistent labels.
What We Discovered in a Real-World RLHF Case Study
In our project, we evaluated thousands of prompt-response pairs. Our mission? Use human judgment to fine-tune an LLM’s behavior across tone, truthfulness, usefulness, and ethical alignment.
Here’s what stood out:
Subjectivity Isn’t One-Dimensional
Even a simple prompt like “Explain quantum mechanics to a child” spawned wildly different answers:
- One was detailed but dense
- Another was fluffy but engaging
- A third sounded like a cartoon script
Each had trade-offs. Only human judgment could weigh them properly.
Guidelines Need to Be Alive
Early on, disagreements were constant. “Helpful” meant different things to different people. So, we kept evolving our annotation playbook — adding examples, clarifying intents, and building shared mental models.
Expertise Levels Mattered
We also asked annotators to self-report their expertise level like beginner, intermediate, or advanced; for each domain. This added critical context to the feedback and helped us calibrate how responses should vary depending on the audience.
Feedback Actually Changed the Model
Our annotations weren’t going into a black box. They shaped the model. We saw measurable improvements in empathy, tone, factual grounding — just from better annotation feedback.
Our Best Practices: What Every AI Team Should Know
If you’re doing subjective labeling at scale, here’s your cheat sheet:
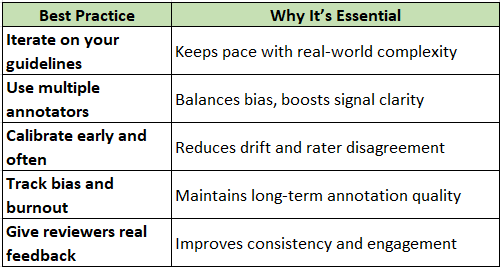
Best Practice: why it’s essential to iterate on your guidelines to keep pace with real-world complexity, use multiple annotators to balance bias and boost signal clarity, calibrate early and often to reduce drift and rater disagreement, and track bias and burnout to maintain long-term annotation quality. Give reviewers real feedback to improve consistency and engagement.
Tools That Actually Get Subjective Work Done
You’ll want platforms that go beyond checkbox labeling. Look for tools that offer:
- Pairwise and ranking options
- Onboarding flows and rater training modules
- Real-time QA and conflict alerts
- Modular review pipelines
Tools like Labelbox, Prodigy, and Scale AI offer some of this out of the box, but custom workflows can be even more powerful if your task is unique.
Want Better Training Data? Scale Quality with Strategy
Here’s how to ensure quality annotation even as your data explodes in size:
- Active Learning: Prioritize uncertain or high-impact samples for human review.
- Semi-Automated Labeling: Let machines suggest labels, and humans verify.
- Feedback Loops: Use past mistakes to refine future guidelines and model behavior.
In our RLHF efforts, active learning helped us pinpoint weak spots in LLM reasoning fast — saving time, money, and headaches.
Human Feedback Isn’t Optional — It’s a Strategic Edge
When done right, subjective annotation does more than clean up data. It creates real differentiation.
- Models become more human-aligned.
- Users get outputs they can trust.
- Companies reduce risk and improve product satisfaction.
For AI leaders, this is the bridge between cutting-edge tech and actually usable products.
Final Take: The Future of AI Needs a Human Backbone
As models grow more complex, getting alignment wrong becomes costlier. Whether it’s a helpful response or a high-stakes decision in healthcare or finance, the quality of your human judgment layer is critical.
And that’s where thoughtful annotation comes in.
From our journey on our project and other RLHF projects, one thing’s clear: subjective annotation isn’t an afterthought — it’s an infrastructure decision.
Let’s Build Smarter AI Together
We provide:
- End-to-end data annotation services, including subjective task handling
- Skilled human intelligence teams trained for LLM alignment and RLHF
- Annotation strategy consulting to help you scale your training data pipelines
Contact us today to explore how we can elevate your AI initiatives with human precision and machine efficiency.

